4. Cloud Infrastructure + VIM Component Level Architecture ¶

Table of Contents ¶
4.1 Introduction. ¶
Chapter 3 introduced the components of an OpenStack-based IaaS
-
Consumable Infrastructure Resources and Services
-
Cloud Infrastructure Management Software (VIM: OpenStack) core services and architectural constructs needed to consume and manage the consumable resources
-
Underlying physical compute, storage and networking resources
This chapter delves deeper into the capabilities of these different resources and their needed configurations to create and operate an OpenStack-based IaaS cloud. This chapter specifies details on the structure of control and user planes, operating systems, hypervisors and BIOS configurations, and architectural details of underlay and overlay networking, and storage, and the distribution of OpenStack service components among nodes. The chapter also covers implementation support for the Reference Model profiles and flavours ; the OpenStack flavor types capture both the sizing and the profile configuration (of the host).
4.2 Underlying Resources ¶
4.2.1 Virtualisation ¶
In OpenStack, KVM is configured as the default hypervisor for compute nodes.
-
Configuration: OpenStack specifies the following KVM configuration steps/instructions to configure KVM:
-
Enable KVM based hardware virtualisation in BIOS. OpenStack provides instructions on how to enable hardware virtualisation for different hardware platforms (x86, Power)
-
QEMU is similar to KVM in that both are libvirt controlled, have the same feature set and utilize compatible virtual machine images
-
-
Configure Compute backing storage
-
Specify the CPU Model for KVM guests (VMs)
-
KVM Performance Tweaks
-
-
-
OpenStack recommends minimizing the code base by removing unused components
-
sVirt (Secure Virtualisation) provides isolation between VM processes, devices, data files and system processes
-
4.2.2. Compute ¶
4.2.2.1. Cloud Deployment (Foundation/management) Node ¶
Minimal configuration: 1 node
4.2.2.2. OpenStack Control Plane Servers (Control Nodes) ¶
-
BIOS Requirements
For OpenStack control nodes we use the BIOS parameters for the basic profile defined in Chapter 5.4 of the Reference Model . Additionally, for OpenStack we need to set the following boot parameters:
|
BIOS/boot Parameter |
Value |
|---|---|
|
Boot disks |
RAID 1 |
|
CPU reservation for host (kernel) |
1 core per NUMA |
|
CPU allocation ratio |
2:1 |
-
How many nodes to meet SLA
-
Minimum 3 nodes for high availability
-
-
HW specifications
-
Boot disks are dedicated with Flash technology disks
-
-
Sizing rules
-
It is easy to horizontally scale the number of control nodes
-
The number of control nodes is determined by a minimum number needed for high availability (viz., 3 nodes) and the extra nodes needed to handle the transaction volumes, in particular, for Messaging service (e.g., RabbitMQ) and Database (e.g., MySQL) to track state.
-
The number of control nodes only needs to be increased in environments with a lot of changes, such as a testing lab, or a very large cloud footprint (rule of thumb: number of control nodes = 3 + quotient(number of compute nodes/1000)).
-
The Services Placement Summary table specifies the number of instances that are required based upon the cloud size (number of nodes).
-
4.2.2.3. Network nodes ¶
Networks nodes are mainly used for L3 traffic management for overlay tenant network (see more detail in section 4.3.1.5 Neutron)
-
BIOS requirements
|
BIOS/boot Parameter |
Value |
|---|---|
|
Boot disks |
RAID 1 |
-
How many nodes to meet SLA
-
Minimum 2 nodes for high availibility using VRRP.
-
-
HW specifications
-
3 NICs card are needed if we want to isolate the different flows:
-
1 NIC for Tenant Network
-
1 NIC for External Network
-
1 NIC for Other Networks (PXE, Mngt …)
-
-
-
Sizing rules
-
Scale out of network node is not easy
-
DVR can be an option for large deployment (see more detail in chapter 4.3.1.5 - Neutron)
-
4.2.2.4. Storage nodes ¶
-
BIOS requirements
|
BIOS/boot Parameter |
Value |
|---|---|
|
Boot disks |
RAID 1 |
-
HW specifications
-
How many nodes to meet SLA
-
Sizing rules
4.2.2.5. Compute Nodes ¶
This section specifies the compute node configurations to support the Basic and High Performance profiles; in OpenStack this would be accomplished by specifying the configurations when creating “flavors”. The cloud operator may choose to implement certain profile-extensions ( RM 2.4 Profile Extensions ) as a set of standard configurations, of a given profile, capturing some of the variability through different values or extra specifications.
-
The software and hardware configurations are as specified in the Reference Model chapter 5.4
-
BIOS requirement
-
The general BIOS requirements are described in the Reference Model chapter 5.4
-
Example Profiles and their Extensions
The Reference Model specifies the Basic (B) and High Performance (H) profile types. The Reference Model also provides a choice of network acceleration capabilities utilising, for example, DPDK and SR-IOV technologies. Table 4-2 lists a few simple examples of profile extensions and some of their capabilities.
|
Pr ofile Exten sions |
D escri ption |
CPU Alloc ation Ratio |
SMT |
CPU Pi nning |
NUMA |
Huge Pages |
Data Tr affic |
|---|---|---|---|---|---|---|---|
|
B1 |
Basic Prof ileNo CPU ov er-su bscri ption pr ofile exte nsion |
1:1 |
Y |
N |
N |
N |
OVS-k ernel |
|
B4 |
Basic Prof ile4x CPU ov er-su bscri ption pr ofile exte nsion |
4:1 |
Y |
N |
N |
N |
OVS-k ernel |
|
HV |
High P erfor mance Pr ofile |
1:1 |
Y |
Y |
Y |
Y |
OVS-k ernel |
|
HD |
High P erfor mance Pr ofile with DPDK pr ofile exte nsion |
1:1 |
Y |
Y |
Y |
Y |
OVS -DPDK |
|
HS |
High P erfor mance Pr ofile with S R-IOV pr ofile exte nsion |
1:1 |
Y |
Y |
Y |
Y |
S R-IOV |
Table 4-2: Profile Extensions and Capabilities
BIOS Settings
A number of capabilities need to be enabled in the BIOS (such as NUMA and SMT); the Reference Model section on “ Cloud Infrastructure Software profile description ” specifies where each of the capabilities is required to be configured. Please note that capabilities may need to be configured in multiple systems. For OpenStack, we also need to set the following boot parameters:
|
BIOS/boot Parameter |
Basic |
High Performance |
|---|---|---|
|
Boot disks |
RAID 1 |
RAID 1 |
-
How many nodes to meet SLA
-
minimum: two nodes per profile
-
-
HW specifications
-
Boot disks are dedicated with Flash technology disks
-
-
In case of DPDK usage:
|
Layer |
Description |
|---|---|
|
Cloud infrastructure |
Important is placement of NICs to get NUMA-balanced system (balancing the I/O, memory, and storage across both sockets), and configuration of NIC features. Server BIOS and Host OS kernel command line settings are described in DPDK release note s and DPDK performance repo rts . Disabling power settings (like Intel Turbo Boost Technology) brings stable performance results, although understanding if and when they benefit workloads and enabling them can achieve better performance results. |
|
Workload |
DPDK uses core affinity along with 1G or 2M Huge Pages, NUMA settings (to avoid crossing inteconnect between CPUs), and DPDK Poll Mode Drivers (PMD, on reserved cores) to get the best performance. DPDK versions xx.11 are Long-Term Support maintained stable release with back-ported bug fixes for a two-year period. |
-
Sizing rules
|
Description |
Mnemonic |
|---|---|
|
Number of CPU sockets |
s |
|
Number of cores |
c |
|
SMT |
t |
|
RAM |
rt |
|
Storage |
d |
|
Overcommit |
o |
|
Average vCPU per instance |
v |
|
Average RAM per instance |
ri |
|
Basic |
High Performance |
||
|---|---|---|---|
|
# of VMs per node (vCPU) |
( s c t*o)/v |
4 (s*c t)/v |
(s c t)/v |
|
# of VMs per node (RAM) |
rt/ri |
rt/ri |
rt/ri |
|
Max # of VMs per node |
min(4* (s c t)/v, rt/ri) |
min( (s c t)/v, rt/ri) |
Caveats:
-
These are theoretical limits
-
Affinity and anti-affinity rules, among other factors, affect the sizing
4.2.2.6. Compute Resource Pooling Considerations ¶
-
Multiple pools of hardware resources where each resource pool caters for workloads of a specific profile (for example, High Performance) leads to inefficient use of the hardware as the server resources are specific to the profile. If not properly sized or when demand changes can lead to oversupply/starvation scenarios; reconfiguration may not be possible because of the underlying hardware or inability to vacate servers for reconfiguration to support another profile type.
-
Single pool of hardware resources including for controllers have the same CPU type. This is operationally efficient as any server can be utilized to support any profile or controller. The single pool is valuable with unpredictable workloads or when the demand of certain profiles is insufficient to justify individual hardware selection.
4.2.2.7. Reservation of Compute Node Cores ¶
The RA-1 2.3.2 Infrastructure Requirements req.inf.com.08 requires the allocation of “certain number of host cores/threads to non-tenant workloads such as for OpenStack services.” A number (“n”) of random cores can be reserved for host services (including OpenStack services) by specifying the following in nova.conf:
reserved_host_cpus = n
where n is any positive integer.
If we wish to dedicate specific cores for host processing we need to consider two different use cases:
1. Require dedicated cores for Guest resources
2. No dedicated cores are required for Guest resources
Scenario #1, results in compute nodes that host both pinned and unpinned workloads. In the OpenStack Train release, scenario #1 is not supported; it may also be something that operators may not allow. Scenario #2 is supported through the specification of the cpu_shared_set configuration. The cores and their sibling threads dedicated to the host services are those that do not exist in the cpu_shared_set configuration.
Let us consider a compute host with 20 cores with SMT enabled (let us disregard NUMA) and the following parameters specified. The physical cores are numbered ‘0’ to ‘19’ while the sibling threads are numbered ‘20’ to ‘39’ where the vCPUs numbered ‘0’ and ‘20’, ‘1’ and ‘21’, etc. are siblings:
cpu_shared_set = 1-7,9-19,21-27,29-39 (can also be specified as cpu_shared_set = 1-19,^8,21-39,^28)
This implies that the two physical cores ‘0’ and ‘8’ and their sibling threads ‘20’ and ‘28’ are dedicated to the host services, and 19 cores and their sibling threads are available for Guest instances (and can be over allocated as per the specified cpu_allocation_ratio in nova.conf.
4.2.2.8. Pinned and Unpinned CPUs ¶
When a VM instance is created the vCPUs are, by default, not assigned to a particular host CPU. Certain workloads require real-time or near real-time behavior viz., uninterrupted access to their cores. For such workloads, CPU pinning allows us to bind an instance’s vCPUs to particular host cores or SMT threads. To configure a flavor to use pinned vCPUs, we use a dedicated CPU policy.
openstack flavor set .xlarge –property hw:cpu_policy=dedicated
While an instance with pinned CPUs cannot use CPUs of another pinned instance, this does not apply to unpinned instances; an unpinned instance can utilize the pinned CPUs of another instance. To prevent unpinned instances from disrupting pinned instances, the hosts with CPU pinning enabled are pooled in their own host aggregate and hosts with CPU pinning disabled are pooled in another non-overlapping host aggregate.
4.2.2.9 Compute node configurations for Profiles and OpenStack Flavors ¶
This section specifies the compute node configurations to support profiles and flavors.
Cloud Infrastructure Hardware Profile
The Cloud Infrastructure Hardware (or simply “host”) profile and configuration parameters are utilised in the reference architecture to define different hardware profiles; these are used to configure the BIOS settings on a physical server and configure utility software (such as Operating System and Hypervisor).
An OpenStack flavor defines the characteristics (“capabilities”) of Virtual Machines (VMs or vServers) that will be deployed on hosts assigned a host-profile. A many to many relationship exists between flavors and host profiles. Multiple flavors can be defined with overlapping capability specifications with only slight variations that VMs of these flavor types can be hosted on similary configured (host profile) compute hosts. Similarly, a VM can be specified with a flavor that allows it to be hosted on, say, a host configured as per the Basic profile or a host configured as per the High Performance profile. Please note that workloads that specify a VM flavor so as to be hosted on a host configured as per the High Performance profile, may not be able to run (adequately with expected performance) on a host configured as per the Basic profile.
A given host can only be assigned a single host profile; a host profile can be assigned to multiple hosts. Host profiles are immutable and hence when a configuration needs to be changed, a new host profile is created.
CPU Allocation Ratio and CPU Pinning
A given host (compute node) can only support a single CPU Allocation Ratio. Thus, to support the B1 and B4 Basic profile extensions with CPU Allocation Ratios of 1.0 and 4.0 we will need to create 2 different host profiles and separate host aggregates for each of the host profiles. The CPU Allocation Ratio is set in the hypervisor on the host.
When the CPU Allocation Ratio exceeds 1.0 then CPU Pinning also needs to be disabled.
Server Configurations
The different networking choices – OVS-Kernel, OVS-DPDK, SR-IOV – result in different NIC port, LAG (Link Aggregation Group), and other configurations. Some of these are shown diagrammatically in the next section.
Leaf and Compute Ports for Server Flavors must align
Compute hosts have varying numbers of Ports/Bonds/LAGs/Trunks/VLANs connected with Leaf ports. Each Leaf port (in A/B pair) must be configured to align with the interfaces required for the compute flavor.
Physical Connections/Cables are generally the same within a zone, regardless of these specific L2/L3/SR-IOV configurations for the compute
Compute Bond Port: TOR port maps VLANs directly with IRBs on the TOR pair for tunnel packets and Control Plane Control and Storage packets. These packets are then routed on the underlay network GRT.
Server Flavors: B1, B4, HV, HD
Compute SR-IOV Port: TOR port maps VLANs with bridge domains that extend to IRBs, using VXLAN VNI. The TOR port associates each packet’s outer VLAN tag with a bridge domain to support VNF interface adjacencies over the local EVPN/MAC bridge domain. This model also applies to direct physical connections with transport elements.
Server Flavors: HS
Notes on SR-IOV
SR-IOV at the Compute Server routes Guest traffic directly with a partitioned NIC card, bypassing the hypervisor and vSwitch software, which provides higher bps/pps throughput for the Guest VM. OpenStack and MANO manage SR-IOV configurations for Tenant VM interfaces.
-
Server, Linux, and NIC card hardware standards include SR-IOV and VF requirements
-
High Performance profile for SR-IOV (hs series) with specific NIC/Leaf port configurations
-
OpenStack supports SR-IOV provisioning
-
Implement Security Policy, Tap/Mirror, QoS, etc. functions in the NIC, Leaf, and other places
Because SR-IOV involves Guest VLANs between the Compute Server and the ToR/Leafs, Guest automation and VM placement necessarily involves the Leaf switches (e.g., access VLAN outer tag mapping with VXLAN EVPN).
-
Local VXLAN tunneling over IP-switched fabric implemented between VTEPs on Leaf switches.
-
Leaf configuration controlled by SDN-Fabric/Global Controller.
-
Underlay uses VXLAN-enabled switches for EVPN support
SR-IOV-based networking for Tenant Use Cases is required where vSwitch-based networking throughput is inadequate.
Example Host Configurations
Host configurations for B1, B4 Profile Extensions
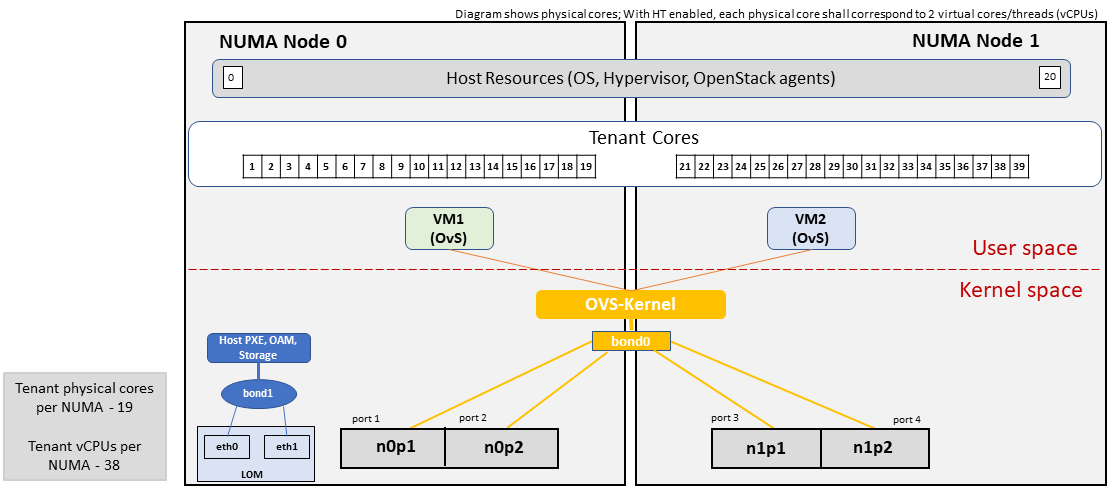 Figure 4-1: Basic Profile Host Configuration (example and simplified).
Figure 4-1: Basic Profile Host Configuration (example and simplified).
Let us refer to the data traffic networking configuration of Figure 4-1 to be part of the hp-B1-a and hp-B4-a host profiles and this requires the configurations as Table 4-3.
|
Configured in |
Host profile: hp-B1-a |
Host profile: hp-B4-a |
|
|---|---|---|---|
|
CPU Allocation Ratio |
Hypervisor |
1:1 |
4:1 |
|
CPU Pinning |
BIOS |
Disable |
Disable |
|
SMT |
BIOS |
Enable |
Enable |
|
NUMA |
BIOS |
Disable |
Disable |
|
Huge Pages |
BIOS |
No |
No |
|
Profile Extensions |
B1 |
B4 |
Table 4-3: Configuration of Basic Flavor Capabilities
Figure 4-2 shows the networking configuration where the storage and OAM share networking but are independent of the PXE network.
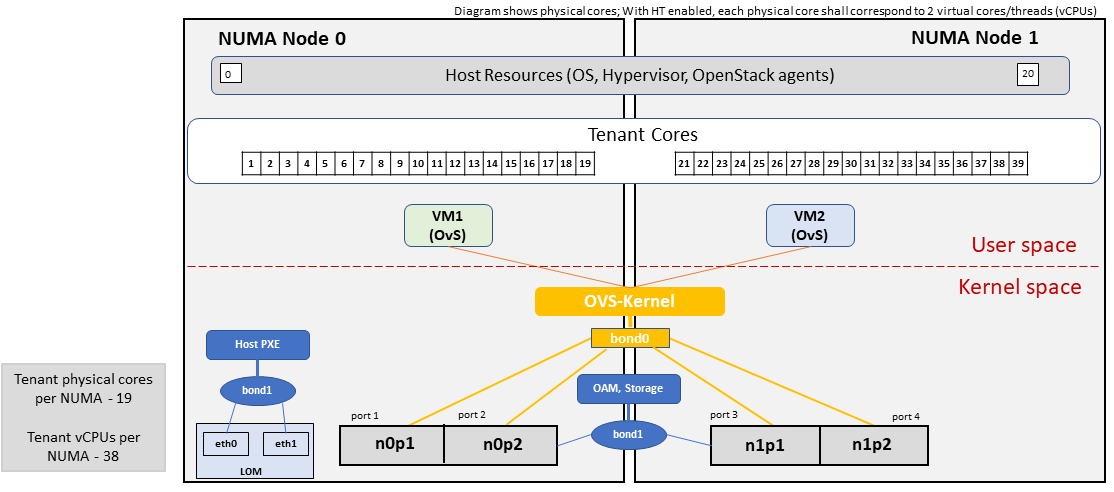 Figure 4-2: Basic Profile Host Configuration with shared Storage and OAM networking (example and simplified).
Figure 4-2: Basic Profile Host Configuration with shared Storage and OAM networking (example and simplified).
Let us refer to the above networking set up to be part of the hp-B1-b and hp-B4-b host profiles but the basic configurations as specified in Table 4-3.
In our example, the Profile Extensions B1 and B4, are each mapped to two different host profiles hp-B1-a and hp-B1-b, and hp-B4-a and hp-B4-b respectively. Different network configurations, reservation of CPU cores, Lag values, etc. result in different host profiles.
To ensure Tenant CPU isolation from the host services (Operating System (OS), hypervisor and OpenStack agents), the following needs to be configured
|
GRUB bootloader Parameter |
Description |
Values |
|---|---|---|
|
isolcpus (Applicable only on Compute Servers) |
A set of cores isolated from the host processes. Contains vCPUs reserved for Tenants |
isolcpus=1-19, 21-39, 41-59, 61-79 |
Host configuration for HV Profile Extensions
The above examples of host networking configurations for the B1 and B4 Profile Extensions are also suitable for the HV Profile Extensions; however, the hypervisor and BIOS settings will be different (see table below) and hence there will be a need for different host profiles. Table 4-4 gives examples of three different host profiles; one each for HV, HD and HS Profile Extensions.
|
Configured in |
Host profile: hp-hv-a |
Host profile: hp-hd-a |
Host profile: hp-hs-a |
|
|---|---|---|---|---|
|
Profile Extensions |
HV |
HD |
HS |
|
|
CPU Allocation Ratio |
Hypervisor |
1:1 |
1:1 |
1:1 |
|
NUMA |
BIOS, Operating System, Hypervisor and OpenStack Nova Scheduler |
Enable |
Enable |
Enable |
|
CPU Pinning (requires NUMA) |
OpenStack Nova Scheduler |
Enable |
Enable |
Enable |
|
SMT |
BIOS |
Enable |
Enable |
Enable |
|
Huge Pages |
BIOS |
Yes |
Yes |
Yes |
Table 4-4: Configuration of High Performance Flavor Capabilities
Host Networking configuration for HD Profile Extensions
An example of the data traffic configuration for the HD (OVS-DPDK) Profile Extensions is shown in Figure 4-3.
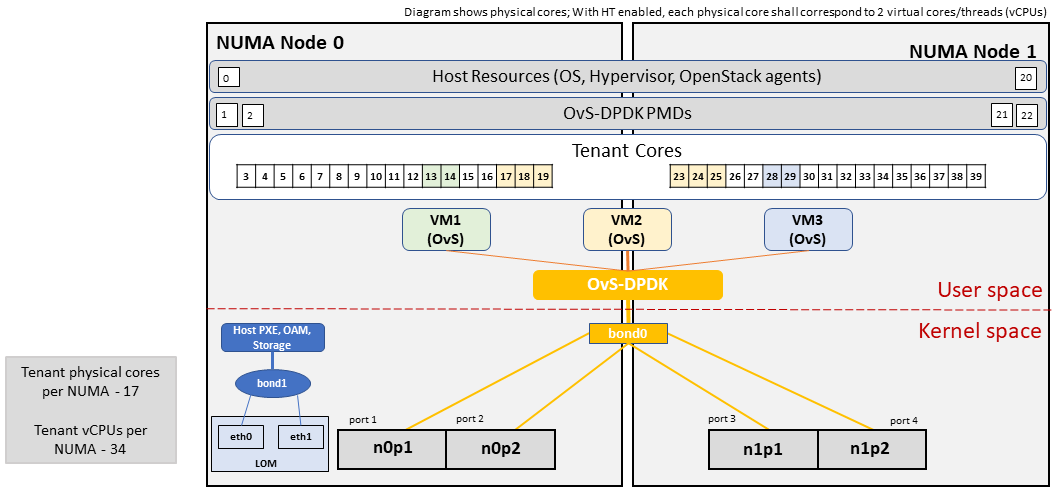 Figure 4-3: High Performance Profile Host Configuration with DPDK acceleration (example and simplified).
Figure 4-3: High Performance Profile Host Configuration with DPDK acceleration (example and simplified).
To ensure Tenant and DPDK CPU isolation from the host services (Operating System (OS), hypervisor and OpenStack agents), the following needs to be configured
|
GRUB bootloader Parameter |
Description |
Values |
|---|---|---|
|
isolcpus (Applicable only on Compute Servers) |
A set of cores isolated from the host processes. Contains vCPUs reserved for Tenants and DPDK |
isolcpus=3-19, 23-39, 43-59, 63-79 |
Host Networking configuration for HS Profile Extensions
An example of the data traffic configuration for the HS (SR-IOV) Profile Extensions is shown in Figure 4-4.
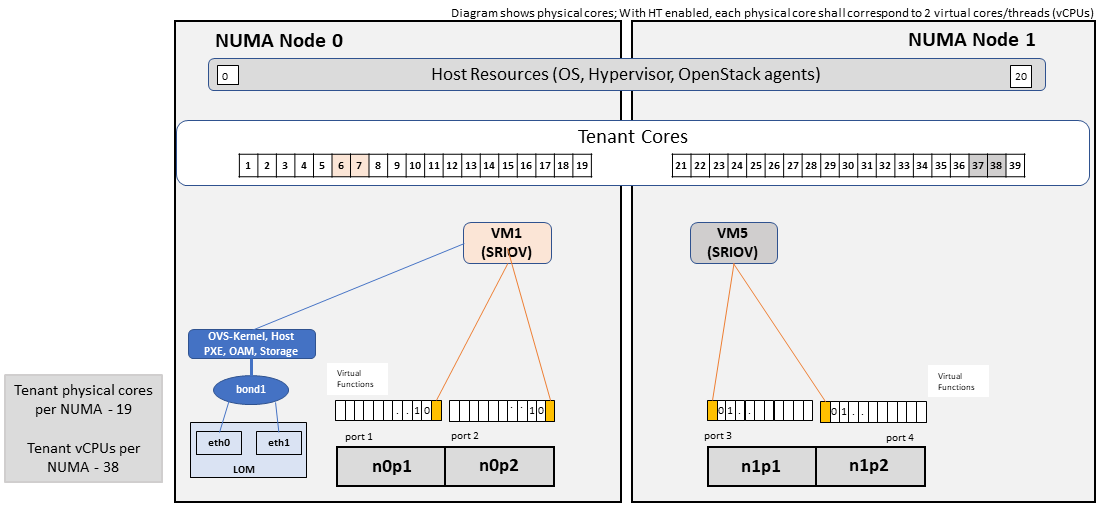 Figure 4-4: High Performance Profile Host Configuration with SR-IOV (example and simplified).
Figure 4-4: High Performance Profile Host Configuration with SR-IOV (example and simplified).
To ensure Tenant CPU isolation from the host services (Operating System (OS), hypervisor and OpenStack agents), the following needs to be configured
|
GRUB bootloader Parameter |
Description |
Values |
|---|---|---|
|
isolcpus (Applicable only on Compute Servers) |
A set of cores isolated from the host processes. Contains vCPUs reserved for Tenants |
isolcpus=1-19, 21-39, 41-59, 61-79 |
Using Hosts of a Host Profile type
As we have seen Profile Extensions are supported by configuring hosts in accordance with the Profile Extensions specifications. For example, an instance of flavor type B1 can be hosted on a compute node that is configured as an hp-B1-a or hp-B1-b host profile. All compute nodes configured with hp-B1-a or hp-B1-b host profile are made part of a host aggregate, say, ha-B1 and thus during VM instantiation of B1 flavor hosts from the ha-B1 host aggregate will be selected.
4.2.3. Network Fabric ¶
Networking Fabric consists of:
-
Physical switches, routers…
-
Switch OS
-
Minimum number of switches
-
Dimensioning for East/West and North/South
-
Spine / Leaf topology – east – west
-
Global Network parameters
-
OpenStack control plane VLAN / VXLAN layout
-
Provider VLANs
4.2.3.1 Physical Network Topology ¶
4.2.3.2 High Level Logical Network Layout ¶
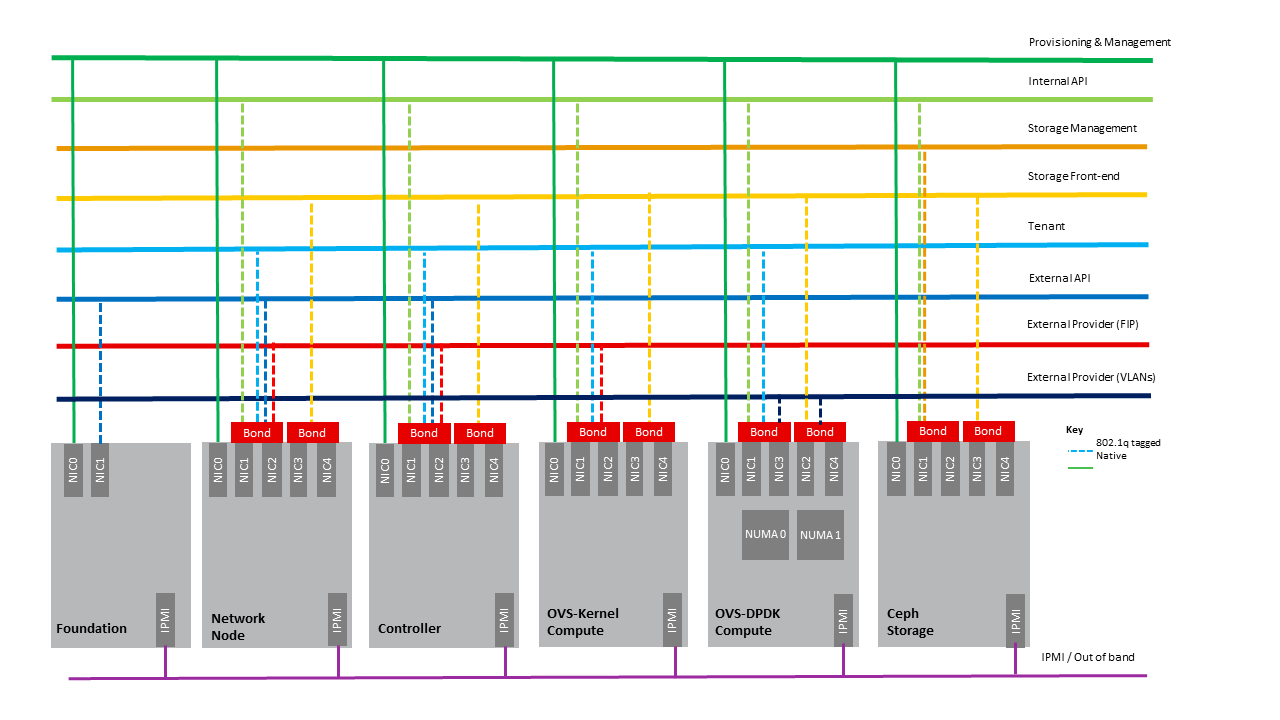 Figure 4-5: Indicative OpenStack Network Layout.
Figure 4-5: Indicative OpenStack Network Layout.
|
Network |
Description |
Characteristics |
|---|---|---|
|
Provisioning & Management |
Initial OS bootstrapping of the servers via PXE, deployment of software and thereafter for access from within the control plane. |
Security Domain: ManagementExternally Routable: NoConnected to: All nodes |
|
Internal API |
Intra-OpenStack service API communications, messaging and database replication |
Security Domain: ManagementExternally Routable: No Connected to: All nodes except foundation |
|
Storage Management |
Backend connectivity between storage nodes for heartbeats, data object replication and synchronisation |
Security Domain: Storage Externally Routable: No Connected to: All nodes except foundation |
|
Storage Front-end |
Block/Object storage access via cinder/swift |
Security Domain: StorageExternally Routable: NoConnected to: All nodes except foundation |
|
Tenant |
VXLAN / Geneve project overlay networks (OVS kernel mode) – i.e. RFC1918 re-usable private networks as controlled by cloud administrator |
Security Domain: UnderlayExternally Routable: No Connected to: controllers and computes |
|
External API |
Hosts the public OpenStack API endpoints including the dashboard (Horizon) |
Security Domain: PublicExternally routable: YesConnected to: controllers |
|
External Provider (FIP) |
Network with a pool of externally routable IP addresses used by neutron routers to NAT to/from the tenant RFC1918 private networks |
Security Domain: Data CentreExternally routable: YesConnected to: controllers, OVS computes |
|
External Provider (VLAN) |
External Data Centre L2 networks (VLANs) that are directly accessible to the project. Note: External IP address management is required |
Security Domain: Data CentreExternally routable: YesConnected to: OVS DPDK computes |
|
IPMI / Out of Band |
The remote “lights-out” management port of the servers e.g. iLO, IDRAC / IPMI / Redfish |
Security Domain: ManagementExternally routable: NoConnected to: IPMI port on all servers |
A VNF application network topology is expressed in terms of VMs, vNIC interfaces with vNet access networks, and WAN Networks while the VNF Application VMs require multiple vNICs, VLANs, and host routes configured within the VM’s Kernel.
4.2.3.3. Octavia v2 API conformant Load Balancing ¶
Load balancing is needed for automatic scaling, managing availability and changes. Octavia is an open-source load balancer for OpenStack, based on HAProxy, and replaces the deprecated (as of OpenStack Queens release) Neutron LBaaS. The Octavia v2 API is a superset of the deprecated Neutron LBaaS v2 API and has a similar CLI for seamless transition.
As a default Octavia utilizes Amphorae Load Balancer. Amphorae consists of a fleet of VMs, containers or bare metal servers and delivers horizontal scaling by managing and spinning these resources on demand. The reference implementation of the Amphorae image is an Ubuntu virtual machine running HAProxy.
Octavia depends upon a number of OpenStack services including Nova for spinning up compute resources on demand and their life cycle management; Neutron for connectivity between the compute resources, project environment and external networks; Keystone for authentication; and Glance for storing of the compute resource images.
Octavia supports provider drivers which allows third-party load balancing drivers (such as F5, AVI, etc.) to be utilized instead of the default Amphorae load balancer. When creating a third-party load balancer, the provider attribute is used to specify the backend to be used to create the load balancer. The list providers lists all enabled provider drivers. Instead of using the provider parameter, an alternate is to specify the flavor_id in the create call where provider-specific Octavia flavors have been created.
4.2.3.4. Neutron Extensions ¶
OpenStack Neutron is an extensible framework that allows incorporation through plugins and API Extensions. API Extensions provides a method for introducing new functionality and vendor specific capabilities. Neutron plugins support new or vendor-specific functionality. Extensions also allow specifying new resources or extensions to existing resources and the actions on these resources. Plugins implement these resources and actions.
Anuket Reference Architecture support the ML2 plugin (see below) as well as the service plugins including for FWaaS (Firewall as a Service) , LBaaS (Load Balancer as a Service) , and VPNaaS (VPN as a Service) . The OpenStack wiki provides a list of Neutron plugins .
Every Neutron plugin needs to implement a minimum set of common methods (actions for Train release) . Resources can inherit Standard Attributes and thereby have the extensions for these standard attributes automatically incorporated. Additions to resources, such as additional attributes, must be accompanied by an extension.
Chapter 5 , Interfaces and APIs, of this Reference Architecture provides a list of Neutron Extensions . The current available extensions can be obtained using List Extensions API and details about an extension using Show extension details API .
Neutron ML2 integration The OpenStack Modular Layer 2 (ML2) plugin simplifies adding networking technologies by utilizing drivers that implement these network types and methods for accessing them. Each network type is managed by an ML2 type driver and the mechanism driver exposes interfaces to support the actions that can be performed on the network type resources. The OpenStack ML2 documentation lists example mechanism drivers.
4.2.3.5. Network quality of service ¶
With support of VNF workloads, the resources bottlenecks are not only the CPU and the memory but also the I/O bandwidth and the forwarding capacity of virtual and non-virtual switches and routers within the infrastructure. Several techniques (all complementary) can be used to improve QoS and try to avoid any issue due to a network bottleneck (mentioned per order of importance):
-
Nodes interfaces segmentation: Have separated NIC ports for Storage and Tenant networks. Actually, the storage traffic is bursty, and especially in case of service restoration after some failure or new service implementation, upgrades, etc. Control and management networks should rely on a separate interface from the interface used to handle tenant networks.
-
Capacity planning: FW, physical links, switches, routers, NIC interfaces and DCGW dimensioning (+ load monitoring: each link within a LAG or a bond shouldn’t be loaded over 50% of its maximum capacity to guaranty service continuity in case of individual failure).
-
Hardware choice: e.g. ToR/fabric switches, DCGW and NIC cards should have appropriate buffering and queuing capacity.
-
High Performance compute node tuning (including OVS-DPDK).
4.2.3.6. Integration Interfaces ¶
-
DHCP When the Neutron-DHCP agent is hosted in controller nodes, then for VMs, on a Tenant network, that need to acquire an IPv4 and/or IPv6 address, the VLAN for the Tenant must be extended to the control plane servers so that the Neutron agent can receive the DHCP requests from the VM and send the response to the VM with the IPv4 and/or IPv6 addresses and the lease time. Please see OpenStack provider Network.
-
DNS
-
LDAP
-
IPAM
4.2.4. Storage Backend ¶
Storage systems are available from multiple vendors and can also utilize commodity hardware from any number of Open Source based storage packages (such as LVM, Ceph, NFS, etc.). The proprietary and open-source storage systems are supported in Cinder through specific plugin drivers. The OpenStack Cinder documentation specifies the minimum functionality that all storage drivers must support. The functions include:
-
Volume: create, delete, attach, detach, extend, clone (volume from volume), migrate
-
Snapshot: create, delete and create volume from snapshot
-
Image: create from volume
The document also includes a matrix for a number of proprietary drivers and some of the optional functions that these drivers support. This matrix is a handy tool to select storage backends that have the optional storage functions needed by the cloud operator. The cloud workload storage requirements helps determine the backends that should be deployed by the cloud operator. The common storage backend attachment methods include iSCSI, NFS, local disk, etc. and the matrix list the supported methods for each of the vendor drivers. The OpenStack Cinder Available Drivers documentation provides a list of all OpenStack compatible drivers and their configuration options.
The Cinder Configuration document provides information on how to configure cinder including Anuket required capabilities for volume encryption, Policy configuration, quotas, etc. The Cinder Administration document provides information on the capabilities required by Anuket including managing volumes, snapshots, multi-storage backends, migrate volumes, etc.
Ceph is the default Anuket Reference Architecture storage backend and is discussed below.
4.2.4.1. Ceph Storage Cluster ¶
The Ceph storage cluster is deployed on bare metal hardware. The minimal configuration is a cluster of three bare metal servers to ensure High availability. The Ceph Storage cluster consists of the following components:
-
CEPH-MON (Ceph Monitor)
-
OSD (object storage daemon)
-
RadosGW (Rados Gateway)
-
Journal
-
Manager
Ceph monitors maintain a master copy of the maps of the cluster state required by Ceph daemons to coordinate with each other. Ceph OSD handle the data storage (read/write data on the physical disks), data replication, recovery, rebalancing, and provides some monitoring information to Ceph Monitors. The RadosGW provides Object Storage RESTful gateway with a Swift-compatible API for Object Storage.
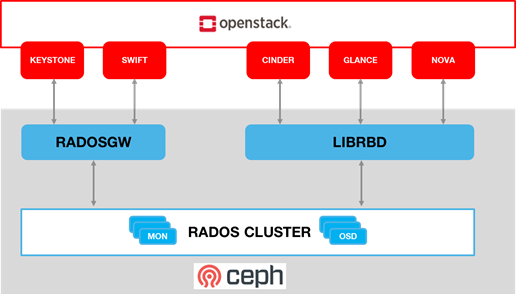
Figure 4-6: Ceph Storage System.
BIOS Requirement for Ceph servers
|
BIOS/boot Parameter |
Value |
|---|---|
|
Boot disks |
RAID 1 |
How many nodes to meet SLA :
-
minimum: three bare metal servers where Monitors are collocated with OSD. Note: at least 3 Monitors and 3 OSDs are required for High AVailability.
HW specifications :
-
Boot disks are dedicated with Flash technology disks
-
For an IOPS oriented cluster (Flash technology ), the journal can be hosted on OSD disks
-
For a capacity oriented cluster (HDD), the journal must be hosted on dedicated Flash technology disks
Sizing rules :
-
Minimum of 6 disks per server
-
Replication factor : 3
-
1 Core-GHz per OSD
-
16GB RAM baseline + 2-3 GB per OSD
4.3 Virtualised Infrastructure Manager (VIM) ¶
This section covers:
-
Detailed breakdown of OpenStack core services
-
Specific build-time parameters
4.3.1 VIM Services ¶
A high level overview of the core OpenStack Services was provided in Chapter 3 . In this section we describe the core and other needed services in more detail.
4.3.1.1 Keystone ¶
Keystone is the authentication service, the foundation of identity management in OpenStack. Keystone needs to be the first deployed service. Keystone has services running on the control nodes and no services running on the compute nodes:
-
Keystone admin API
-
Keystone public API – in Keystone V3 this is the same as the admin API,
4.3.1.2 Glance ¶
Glance is the image management service. Glance has only a dependency on the Keystone service therefore it is the second one deployed. Glance has services running on the control nodes and no services running on the compute nodes:
-
Glance API
-
Glance Registry
The Glance backends include Swift, Ceph RBD and NFS
4.3.1.3 Cinder ¶
Cinder is the block device management service, Cinder depends on Keystone and possibly Glance to be able to create volumes from images. Cinder has services running on the control nodes and no services running on the compute nodes:
-
Cinder API
-
Cinder Scheduler
-
Cinder Volume – the Cinder volume process needs to talk to its backends
The Cinder backends include SAN/NAS storage, iSCSI drives, Ceph RBD and NFS.
4.3.1.4 Swift ¶
Swift is the object storage management service, Swift depends on Keystone and possibly Glance to be able to create volumes from images. Swift has services running on the control nodes and the compute nodes:
-
Proxy Services
-
Object Services
-
Container Services
-
Account Services
The Swift backends include iSCSI drives, Ceph RBD and NFS.
4.3.1.5 Neutron ¶
Neutron is the networking service, Neutron depends on Keystone and has services running on the control nodes and the compute nodes. Depending upon the workloads to be hosted by the Infrastructure and the expected load on the controller node, some of the Neutron services can run on separate network node(s). Factors affecting controller node load include number of compute nodes and the number of API calls being served for the various OpenStack services (nova, neutron, cinder, glance etc.). To reduce controller node load, network nodes are widely added to manage L3 traffic for overlay tenant networks and interconnection with external networks. Table 4-2 below lists the networking service components and their placement. Please note that while network nodes are listed in the table below, network nodes only deal with tenant networks and not provider networks. Also, network nodes are not required when SDN is utilized for networking.
|
Networking Service component |
Description |
Required or Optional Service |
Placement |
|---|---|---|---|
|
neutron server ( neutron-server and neu tron- * -plugin) |
Manages user requests and exposes the Neutron APIs |
Required |
Controller node |
|
DHCP agent (neutr on-dhcp-agent) |
Provides DHCP services to tenant networks and is responsible for maintaining DHCP configuration. For High availability, multiple DHCP agents can be assigned. |
Optional depending upon plug-in |
Network node (Controller node if no network node present) |
|
L3 agent (neu tron-l3-agent) |
Provides L3/NAT forwarding for external network access of VMs on tenant networks and supports services such as Firewal l-as-a-service (FWaaS) and Load Balance r-as-a-service (LBaaS) |
Optional depending upon plug-in |
Network node (Controller node if no network node present) NB in DVR based OpenStack Networking, also in all Compute nodes. |
|
neutron metadata agent (neutron-m etadata-agent) |
The metadata service provides a way for instances to retrieve ins tance-specific data. The networking service, neutron, is responsible for intercepting these requests and adding HTTP headers which uniquely identify the source of the request before forwarding it to the metadata API server. These functions are performed by the neutron metadata agent. |
Optional |
Network node (Controller node if no network node present) |
|
neutron plugin agent (ne utron- * -agent) |
Runs on each compute node to control and manage the local virtual network driver (such as the Open vSwitch or Linux Bridge) configuration and local networking configuration for VMs hosted on that node. |
Required |
Every Compute Node |
Table 4-2: Neutron Services Placement
Issues with the standard networking (centralized routing) approach
The network node performs both routing and NAT functions and represents both a scaling bottleneck and a single point of failure.
Two VMs on different compute nodes and using different project networks (a.k.a. tenant networks) where the both of the project networks are connected by a project router. For communication between the two VMs (instances with a fixed or floating IP address), the network node routes East-West network traffic among project networks using the same project router. Even though the instances are connected by a router, all routed traffic must flow through the network node, and this becomes a bottleneck for the whole network.
While the separation of the routing function from the controller node to the network node provides a degree of scaling it is not a truly scalable solution. We can either add additional cores/compute-power or network node to the network node cluster, but, eventually, it runs out of processing power especially with high throughput requirement. Therefore, for scaled deployments, there are multiple options including use of Dynamic Virtual Routing (DVR) and Software Defined Networking (SDN).
Distributed Virtual Routing (DVR)
With DVR, each compute node also hosts the L3-agent (providing the distributed router capability) and this then allows direct instance to instance (East-West) communications.
The OpenStack “ High Availability Using Distributed Virtual Routing (DVR) ” provides an in depth view into how DVR works and the traffic flow between the various nodes and interfaces for three different use cases. Please note that DVR was introduced in the OpenStack Juno release and, thus, its detailed analysis in the Liberty release documentation is not out of character for OpenStack documentation.
DVR addresses both scalability and high availability for some L3 functions but is not fully fault tolerant. For example, North/South SNAT traffic is vulnerable to single node (network node) failures. DVR with VRRP addresses this vulnerability.
Software Defined Networking (SDN)
For the most reliable solution that addresses all the above issues and Telco workload requirements requires SDN to offload Neutron calls.
SDN provides a truly scalable and preferred solution to suport dynamic, very large-scale, high-density, telco cloud environments. OpenStack Neutron, with its plugin architecture, provides the ability to integrate SDN controllers ( 3.2.5. Virtual Networking – 3rd party SDN solution ). With SDN incorporated in OpenStack, changes to the network is triggered by workloads (and users), translated into Neutron APIs and then handled through neutron plugins by the corresponding SDN agents.
4.3.1.6 Nova ¶
Nova is the compute management service, Nova depends on all above components and is deployed after. Nova has services running on the control nodes and the compute nodes:
-
nova-metadata-api
-
nova-compute api
-
nova-consoleauth
-
nova-scheduler
-
nova-conductor
-
nova-novncproxy
-
nova-compute-agent which runs on Compute node
Please note that the Placement-API must have been installed and configured prior to nova compute starts.
4.3.1.7 Ironic ¶
Ironic is the bare metal provisioning service. Ironic depends on all above components and is deployed after. Ironic has services running on the control nodes and the compute nodes:
-
Ironic API
-
ironic-conductor which executes operation on bare metal nodes
Note: This is an optional service. As Ironic is currently not invoked directly (only invoked through other services such as Nova) hence its APIs will not be specified.
4.3.1.8 Heat ¶
Heat is the orchestration service using template to provision cloud resources, Heat integrates with all OpenStack services. Heat has services running on the control nodes and no services running on the compute nodes:
-
heat-api
-
heat-cfn-api
-
heat-engine
4.3.1.9 Horizon ¶
Horizon is the Web User Interface to all OpenStack services. Horizon has services running on the control nodes and no services running on the compute nodes.
4.3.1.10 Placement ¶
The OpenStack Placement service enables tracking (or accounting) and scheduling of resources. It provides a RESTful API and a data model for the managing of resource provider inventories and usage for different classes of resources. In addition to standard resource classes, such as vCPU, MEMORY_MB and DISK_GB, the Placement service supports custom resource classes (prefixed with “ CUSTOM_ ”) provided by some external resource pools such as a shared storage pool provided by, say, Ceph. The placement service is primarily utilized by nova-compute and nova-scheduler. Other OpenStack services such as Neutron or Cyborg can also utilize placement and do so by creating Provider Trees . The following data objects are utilized in the placement service :
Resource Providers provide consumable inventory of one or more classes of resources (CPU, memory or disk). A resource provider can be a compute host, for example.
Resource Classes specifies the type of resources (vCPU, MEMORY_MB and DISK_GB or CUSTOM_*)
Inventory: Each resource provider maintains the total and reserved quantity of one or more classes of resources. For example, RP_1 has available inventory of 16 vCPU, 16384 MEMORY_MB and 1024 DISK_GB.
Traits are qualitative characteristics of the resources from a resource provider. For example, the trait for RPA_1 “is_SSD” to indicate that the DISK_GB provided by RP_1 are solid state drives.
Allocations represent resources that have been assigned/used by some consumer of that resource.
Allocation candidates is the collection of resource providers that can satisfy an allocation request.
The Placement API is stateless and, thus, resiliency, availability and scaling, it is possible to deploy as many servers as needed. On start, the nova-compute service will attempt to make a connection to the Placement API and keep attempting to connect to the Placement API, logging and warning periodically until successful. Thus, the Placement API must be installed and enabled prior to Nova compute.
Placement has services running on the control node:
-
nova-placement-api
4.3.1.11 Barbican ¶
Barbican is the OpenStack Key Manager service. It is an optional service hosted on controller nodes. It provides secure storage, provisioning and management of secrets as passwords, encryption keys and X.509 Certificates. Barbican API is used to centrally manage secrets used by OpenStack services, e.g. symmetric encryption keys used for Block storage encryption or Object Storage encryption or asymmetric keys and certificates used for Glance image signing and verification.
Barbican usage provides a means to fulfill security requirements such as sec.sys.012 “The Platform must protect all secrets by using strong encryption techniques and storing the protected secrets externally from the component” and sec.ci.001 “The Platform must support Confidentiality and Integrity of data at rest and in transit.”.
4.3.2. Containerised OpenStack Services ¶
Containers are lightweight compared to Virtual Machines and leads to efficient resource utilization. Kubernetes auto manages scaling, recovery from failures, etc. Thus, it is recommended that the OpenStack services be containerized for resiliency and resource efficiency.
In Chapter 3, Figure 3.2 shows a high level Virtualised OpenStack services topology. The containerized OpenStack services topology version is shown in Figure 4-7.
{kind=link}
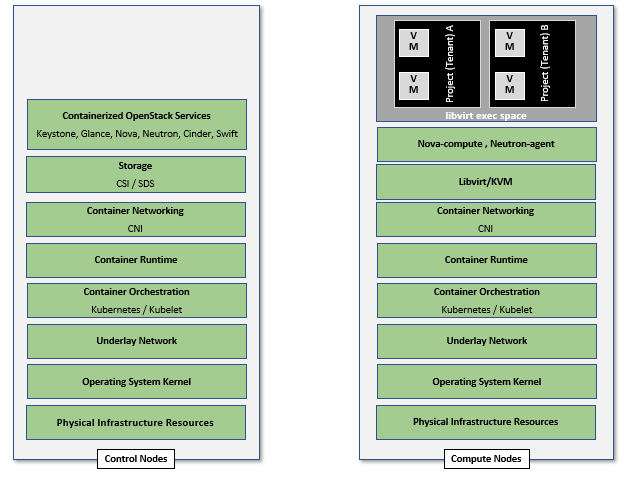
Figure 4-7: Containerised OpenStack Services Topology.
4.4 Consumable Infrastructure Resources and Services ¶
4.4.1. Support for Cloud Infrastructure Profiles and flavors ¶
Reference Model Chapter 4 and 5 provide information about the Cloud Infrastructure Profiles and their size information. OpenStack flavors with their set of properties describe the VM capabilities and size required to determine the compute host which will run this VM. The set of properties must match compute profiles available in the infrastructure. To implement these profiles and sizes, it is required to set up the flavors as specified in the tables below.
|
Flavor Capabilities |
ReferenceRM Chapter 4 and 5 |
Basic |
High Performance |
|---|---|---|---|
|
CPU allocation ratio (custom extra_specs) |
inf ra.com.cfg.001 |
In flavor create or flavor set –property cpu_alloca tion_ratio=4.0 |
In flavor create or flavor set –property cpu_alloca tion_ratio=1.0 |
|
NUMA Awareness |
inf ra.com.cfg.002 |
In flavor create or flavor set spe cify–property hw:numa_ nodes=<integer range of 0 to #numa_nodes – 1>To restrict an instance’s vCPUs to a single host NUMA node, specify: –property hw:nu ma_nodes=1Some compute intensive* workloads with highly sensitive memory latency or bandwidth requirements, the instance may benefit from spreading across multiple NUMA nodes: –property h w:numa_nodes=2 |
|
|
CPU Pinning |
inf ra.com.cfg.003 |
In flavor create or flavor set specify –property hw:cpu _policy=shared (default) |
In flavor create or flavor set specify –property hw:cpu_po licy=dedicated and–property hw:cpu__ thread_policy= <prefer, require, isolate>Use “isolate” thread policy for very high compute intensive workloads that require that each vCPU be placed on a different physical core |
|
Huge Pages |
inf ra.com.cfg.004 |
–property hw:mem_pa ge_size=<small |large | size> |
|
|
SMT |
inf ra.com.cfg.005 |
In flavor create or flavor set specify –property hw:cpu_th reads=<integer #threads (usually 1 or 2)> |
|
|
OVS-DPDK |
infra.n et.acc.cfg.001 |
ml2.conf.ini configured to support [OVS] datapa th_type=netdev Note: huge pages should be configured to large |
|
|
Local Storage SSD |
infra.hw.s tg.ssd.cfg.002 |
tra it:STORAGE_DIS K_SSD=required |
tra it:STORAGE_DIS K_SSD=required |
|
Port speed |
infra. hw.nic.cfg.002 |
–property quota vif_inbound_a verage=1310720 andvif_o utbound_averag e=1310720Note: 10 Gbps = 1250000 kilobytes per second |
–property quota vif_inbound_a verage=3125000 and vif_o utbound_averag e=3125000Note: 25 Gbps = 3125000 kilobytes per second |
For example as defined in Reference Model Profile Extensions .
In addition, to configure the storage IOPS the following two parameters need to be specified in the flavor create: –property quota:disk_write_iops_sec=<IOPS#> and –property quota:disk_read_iops_sec=<IOPS#>.
The flavor create command and the mandatory and optional configuration parameters is documented in https://docs.openstack.org/nova/latest/user/flavors.html .
4.4.2. Logical segregation and high availability ¶
To Ensure Logical segregation and high availability, the architecture will rely on the following principles:
-
Availability zone: provide resiliency and fault tolerance for VNF deployments, by means of physical hosting distribution of Compute Nodes in separate racks with separate power supply, in the same or different DC room
-
Affinity-groups: allow tenants to make sure that VNFC instances are on the same compute node or are on different compute nodes.
Note: The Cloud Infrastructure doesn’t provide any resiliency mechanisms at the service level. Any VM restart shall be triggered by the VNF Manager instead of OpenStack:
-
It doesn’t implement Instance High Availability which could allow OpenStack Platform to automatically re-spawn instances on a different Compute node when their host Compute node breaks.
-
Physical host reboot does not trigger automatic VM recovery.
-
Physical host reboot does not trigger the automatic start of VM
Limitations and constraints
-
NUMA Overhead: isolated core will be used for overhead tasks from the hypervisor
4.4.3. Transaction Volume Considerations ¶
Storage transaction volumes impose a requirement on North-South network traffic in and out of the storage backend. Data availability requires that the data be replicated on multiple storage nodes and each new write imposes East-West network traffic requirements.
4.5 Cloud Topology and Control Plane Scenarios ¶
Typically, Clouds have been implemented in large (central) data centers with 100’ to tens of thousands of servers. Telco Operators have also been creating intermediate data centers in central office locations, colocation centers, and now edge centers at the physical edge of their networks because of the demand for low latency and high throughput for 5G, IoT and connected devices (including autonomous driverless vehicles and connected vehicles). Chapter 3 of this document, discusses Cloud Topology and lists 3 types of data centers: Large, Intermediate and Edge.
For ease of convenience, unless specifically required, in this section we will use Central Cloud Center, Edge Cloud Center and Intermediate Cloud Center as representative terms for cloud services hosted at centralised large data centers, Telco edge locations and for locations with capacity somewhere in between the large data centers and edge locations, respectively. The mapping of various terms, including the Reference Model terminology specified in Table 8-5 and Open Glossary of Edge Computing is as follows:
-
Central Cloud Center: Large Centralised Data Center, Regional Data Center
-
Intermediate Cloud Center: Metro Data Center, Regional Edge, Aggregation Edge
-
Edge Cloud Center: Edge, Mini-/Micro-Edge, Micro Modular Data Center, Service Provider Edge, Access Edge, Aggregation Edge
In the Intermediate and Edge cloud centers, there may be limitations on the resource capacity, as in the number of servers, and the capacity of these servers in terms of # of cores, RAM, etc. restricting the set of services that can be deployed and, thus, creating a dependency between other data centers. In Reference Model Chapter 8.3 , Table 8-5 specifies the physical and environmental characteristics, infrastructure capabilities and deployment scenarios of different locations.
Chapter 3.3.1.1. OpenStack Services Topology of this document, specifies the differences between the Control Plane and Data Plane, and specifies which of the control nodes, compute nodes, storage nodes (optional) and network nodes (optional) are components of these planes. The previous sections of Chapter 4 include a description of the OpenStack services and their deployment in control nodes, compute nodes, and optionally storage nodes and network nodes (rarely). The Control Plane deployment scenarios determine the distribution of OpenStack and other needed services among the different node types. This section considers the Centralised Control Plane (CCP) and Distributed Control Plane (DCP) scenarios. The choice of control plane and the cloud center resource capacity and capabilities determine the deployment of OpenStack services in the different node types.
The Central Cloud Centers are organized around a Centralised Control Plane. With the introduction of Intermediate and Edge Cloud Centers, the Distributed Control Plane deployment becomes a possibility. A number of independent control planes (sometimes referred to as Local Control Planes (LCP)) exist in the Distributed Control Plane scenario, compared with a single control plane in the Centralised Control Plane scenario. Thus, in addition to the control plane and controller services deployed at the Central Cloud Center, Local Control Planes hosting a full-set or subset of the controller services are also deployed on the Intermediate and Edge Cloud Centers. Table 4-5 presents examples of such deployment choices.
|
Orc hestr ation |
Ide ntity Manag ement |
Image Manag ement |
Co mpute |
Ne twork Manag ement |
St orage Manag ement |
||
|---|---|---|---|---|---|---|---|
|
CCP |
C entra lised DC – co ntrol nodes |
heat -api, heat- engin e,nov a-pla cemen t-api |
Ide ntity Pro vider (IdP ),Key stone API |
G lance API, G lance Reg istry |
no va-co mpute api ,nova -sche duler ,nova -cond uctor |
ne utron -serv er,ne utron -dhcp -agen t,neu tron- L2-ag ent,n eutro n-L3- agent (op tiona l),ne utron -meta data- agent |
C inder API,C inder S chedu ler,C inder V olume |
|
DCP: c ombin ation of ser vices depe nding upon C enter size |
Any DC - Co ntrol nodes O ption 1 |
heat -api, heat- engin e,nov a-pla cemen t-api |
Ide ntity Pro vider (IdP ),Key stone API |
G lance API, G lance Reg istry |
no va-co mpute api ,nova -sche duler ,nova -cond uctor |
ne utron -serv er,ne utron -dhcp -agen t,neu tron- L2-ag ent,n eutro n-L3- agent (op tiona l),ne utron -meta data- agent |
C inder API,C inder S chedu ler,C inder V olume |
|
Any DC - Co ntrol nodes O ption 2: split ser vices be tween DCs |
** in other DC |
* in Large DC |
* in Large DC |
** in an other DC |
** in an other DC |
** in an other DC |
|
|
CCP or DCP |
Co mpute nodes |
nov a-com pute- agent |
ne utron -L2-a gent, n eutro n-L3- agent (opti onal) |
||||
|
CCP |
Co mpute nodes |
nov a-pla cemen t-api |
nov a-com pute- agent ,nova -cond uctor |
ne utron -serv er,ne utron -dhcp -agen t,neu tron- L2-ag ent,n eutro n-L3- agent (opti onal) |
Table 4-5: Distribution of OpenStack services on different nodes depending upon Control Plane Scenario
4.5.1 Edge Cloud Topology ¶
The Reference Model Chapter 8.3 “ Telco Edge Cloud ”, presents the deployment environment characteristics, infrastructure characteristics and new values for the Infrastructure Profiles at the Edge.
The Edge computing whitepaper includes information such as the services that run on various nodes. The information from the whitepaper coupled with that from the OpenStack Reference Architecture for 100, 300 and 500 nodes will help in deciding which OpenStack and other services (such as database, messaging) run on which nodes in what Cloud Center and the number of copies that should be deployed. These references also present the pros and cons of DCP and CCP and designs to address some of the challenges of each of the models.
Table 8-4 in the Reference Model Chapter 8.3.4 “ Telco Edge Cloud: Platform Services Deployment ” lists the Platform Services that may be placed in the different node types (control, compute and storage). Depending upon the capacity and resources available only the compute nodes may exist at the Edge thereby impacting operations.
Table 8-3 in the Reference Model Chapter 8.3.3 “ Telco Edge Cloud Infrastructure Profiles ”, lists a number of Infrastructure Profile characteristics and the changes that may need to be made for certain Edge clouds depending upon their resource capabilities. It should be noted that none of these changes affect the definition of OpenStack flavours.
4.5.1.1 Edge Cloud Deployment ¶
Deployment at the Edge requires support for large scale deployment. A number of open-source tools are available for the purpose including:
-
Airship : declaratively configure, deploy and maintain an integrated virtualization and containerization platform
-
Starling-X : cloud infrastructure software stack for the edge
-
Triple-O : for installing, upgrading and operating OpenStack clouds
The Reference Implementation (RI1) is responsible to choose the tools for the implementation and shall specify implementation and usage details of the chosen tools.